Machine learning and ML lifecycle are different from traditional programming and software development lifecycle. Since ML is new and different, we do not yet understand it as well as traditional software.
Machine Learning Project Failure Rate
Before embarking on building ML applications, studying why ML projects fail can improve the chances of success. Sample this:
-
Jan 2019: Gartner predicted that through 2020, 80% of AI projects will remain alchemy, run by wizards and through 2022, only 20% of analytic insights will deliver business outcomes.
-
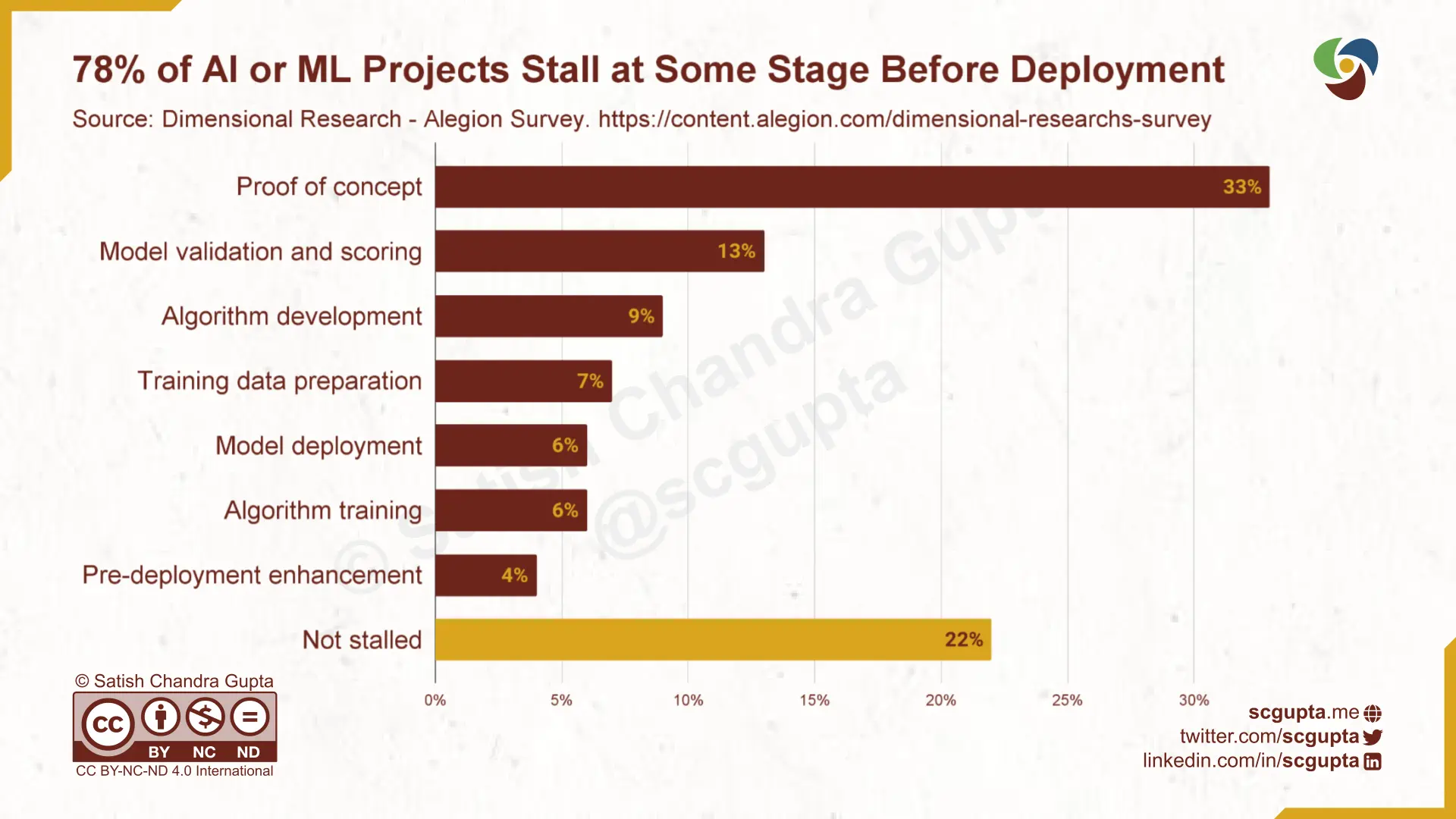
May 2019: Dimensional Research — Alegion Survey reported 78% of AI or ML projects stall at some stage before deployment, and 81% admit the process of training AI with data is more difficult than they expected.
-
July 2019: VentureBeat reported 87% of data science projects never make it into production.
-
July 2019: International Data Corporation (IDC) survey found that a quarter of organizations reported up to 50% AI project failure rate.
-
Sep 2020: According to survey of senior executives in Driving ROI Through AI report by ESI ThoughtLab, about one-quarter of AI projects are now in widespread deployment among AI leaders; among companies in earlier stages of AI development, the number is less than two in ten.
-
Oct 2020: Gartner research showed only 53% of projects make it from artificial intelligence (AI) prototypes to production
Failure is inevitable when attempting anything new and hard, but these are alarmingly high rates. In fact, so high that it is reasonable to be skeptical.
I can’t help but recall similar claims about software development in the 1990s. The Standish Group’s CHAOS Report in 1994 claimed that only 16% of the software projects succeeded. Such a high failure rate was doubted, and over years CHAOS report has become more nuanced. But still, only 36% of projects were reported as a success, 45% as challenged, and 19% failed in the 2015 report.
Though the exact percentage was doubted, there was a broad agreement that the software project failure rate was unacceptably high. This led to the product management and development process evolution to improve the success rate.
High ML Project Failure Rate is Real
Even if the ML project failure rate is not ~80% (for example, failure at the Proof of Concept stage is a good thing), the “real” failure rate is quite likely still very high.
This story is repeated so very often:
- A data scientist is brought in to do ML on the data being collected.
- She discovers that the data is unusable. Either nobody knows what it is, or it is incomplete and unreliable.
- Somehow she manages to clean the data; experiment, and build a model. She has it all in her Jupyter notebook.
- Management considers it done and ready to deploy. Only to learn that significant work is needed to take it to production.
- Disappointed management says, “okay, do it.” The data scientist replies, “she can’t, engineers have to do it.” And engineers are like, “who, me? this math?”
- Nobody is yet realizing that it is NOT done even after deployment. The model must be monitored for data drift and retrained.
- Nobody is happy in the end. Management thinks ML is a hoax. Data Scientist thinks they don’t get it.
Why Machine Learning Projects Fail
ML project failures can happen due to multiple reasons. Some of the most common causes are explained below.
1. Solving the Wrong Problem
Your ML project is guaranteed to fail if you do not choose the problem wisely. It does not matter that you have trained the best model that generalizes well. The most important ingredient of a successful ML project is to pick a problem that end users care about and is important for the business.
If you are attacking an important pain point that is making customers not spend on your business, you have picked the right battle. Now if you formulate your ML problem such that it aligns with the business objectives, you have won half the battle!
2. Not Having the Right Data
Once you have selected the right problem, the battle shifts to have the needed data. There can be two causes: access to the data and collecting the right data.
- Not Having Access to the Data: This can be due to beurecretic organizational issues. You will have to navigate through the process. But it can also be due to the sensitivity of the data, especially in highly regulated industries (e.g. healthcare). You have to see if you anonymize the data, or strip it to only necessary attributes. It may even force you to rethink how you formulate your ML problem.
- Not Collecting the Right Data: It is quite possible that your business is collecting a lot of data but not collecting some key piece of info. For example, user action while using an ML-assisted product feature can be a crucial indicator and help you improve your model. Did the user click on one of the recommendations? Which one? If not, what did the user search for after that?
- Poor Quality of the Data: You may have a lot of data but very little usable data. Because the collected data is unreliable and it has turned your Data Lake into Data Swamp. The paradox of data abundance coexisting with the scarcity of useful and usable data. Data access, insufficiency, quality, collection, and curation issues.
3. Lack of Ownership
It may be that different people own different parts, but there is no consolidated ownership of the overall success. Your data scientists have “thrown the model over the wall” and think their job is done. Your engineers may have made some changes in the product and user experience that reduces the utility or efficacy of the ML model.
There can be hundreds of reasons. Without consolidating data scientists and engineers to own it end-to-end, the project is an orphan.
4. Can’t Deploy
Your project may fail due to infeasibility or the high cost of deploying it in production. This typically happens when data scientists go for the fanciest ML model without considering non-functional requirements (e.g. inference latency, model explainability legal requirements, bias in model results). This is a classic case of “Operation Successful but Patient Dead.”
5. Data and Concept Drift
Once the model is deployed, everyone celebrates and moves on (well, to building other models). Model performance degrades over time and the model is not retrained, or some pipeline has silently broken. After a while, the model is taken off from production. Just like code, ML models need to be monitored and fixed when broken.
How to Improve Success Rate
We can apply lessons learned in software development:
- Consolidate Ownership: Cross-functional team responsible for the end-to-end project.
- Integrate Early: Implement a simple (rule-based or dummy) model and develop end-to-end product feature first.
- Iterate Often: Build better models and replace the simple model, monitor, and repeat.
Additionally, since data is the foundation for Machine Learning:
- Begin with Data Collection: Implement a data strategy
- Solve Simple Problems First: Walk before you run
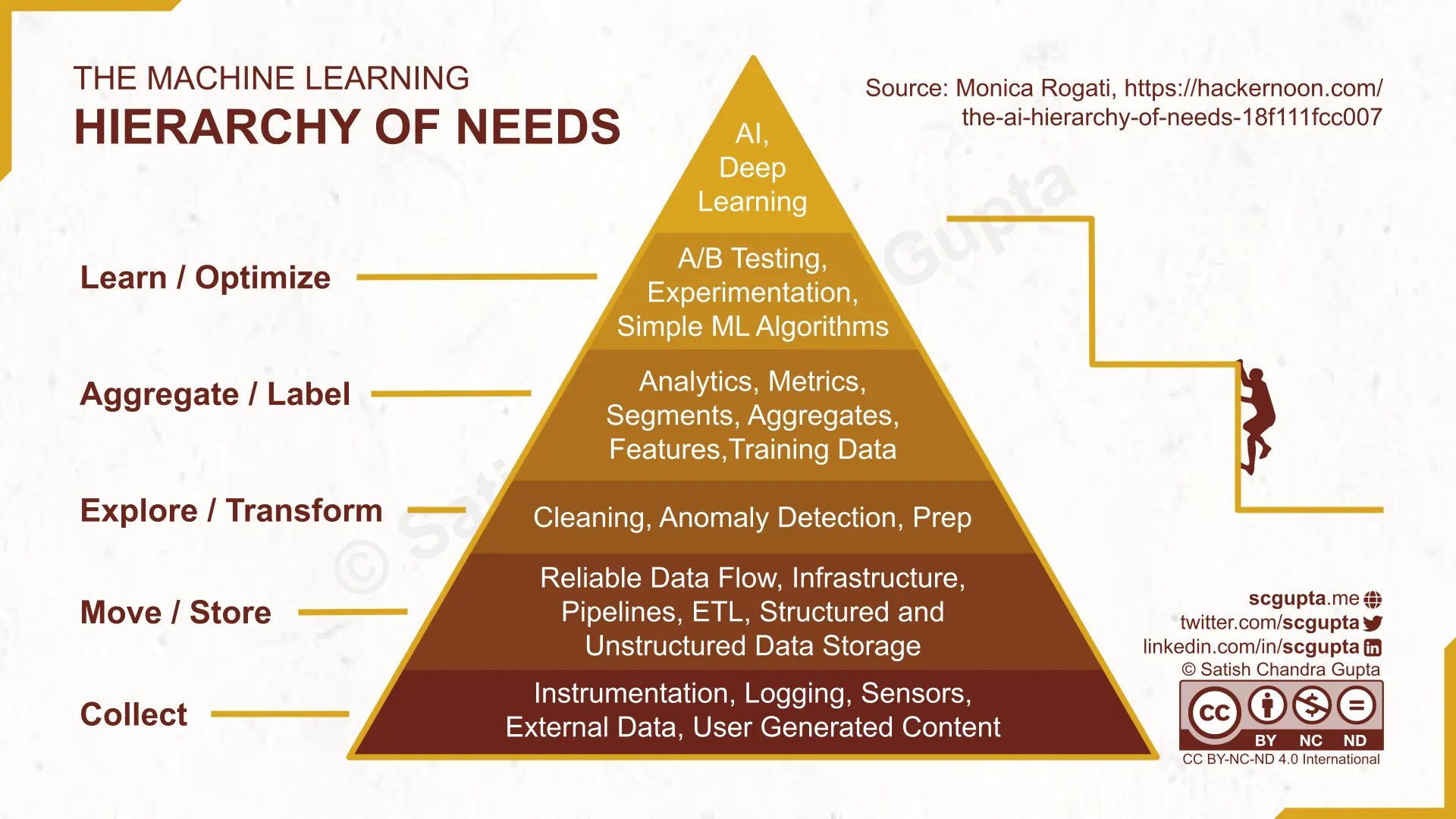
This is beautifully captured in The Data Science / Machine Learning / AI Hierarchy of Need: