What is MLOps?
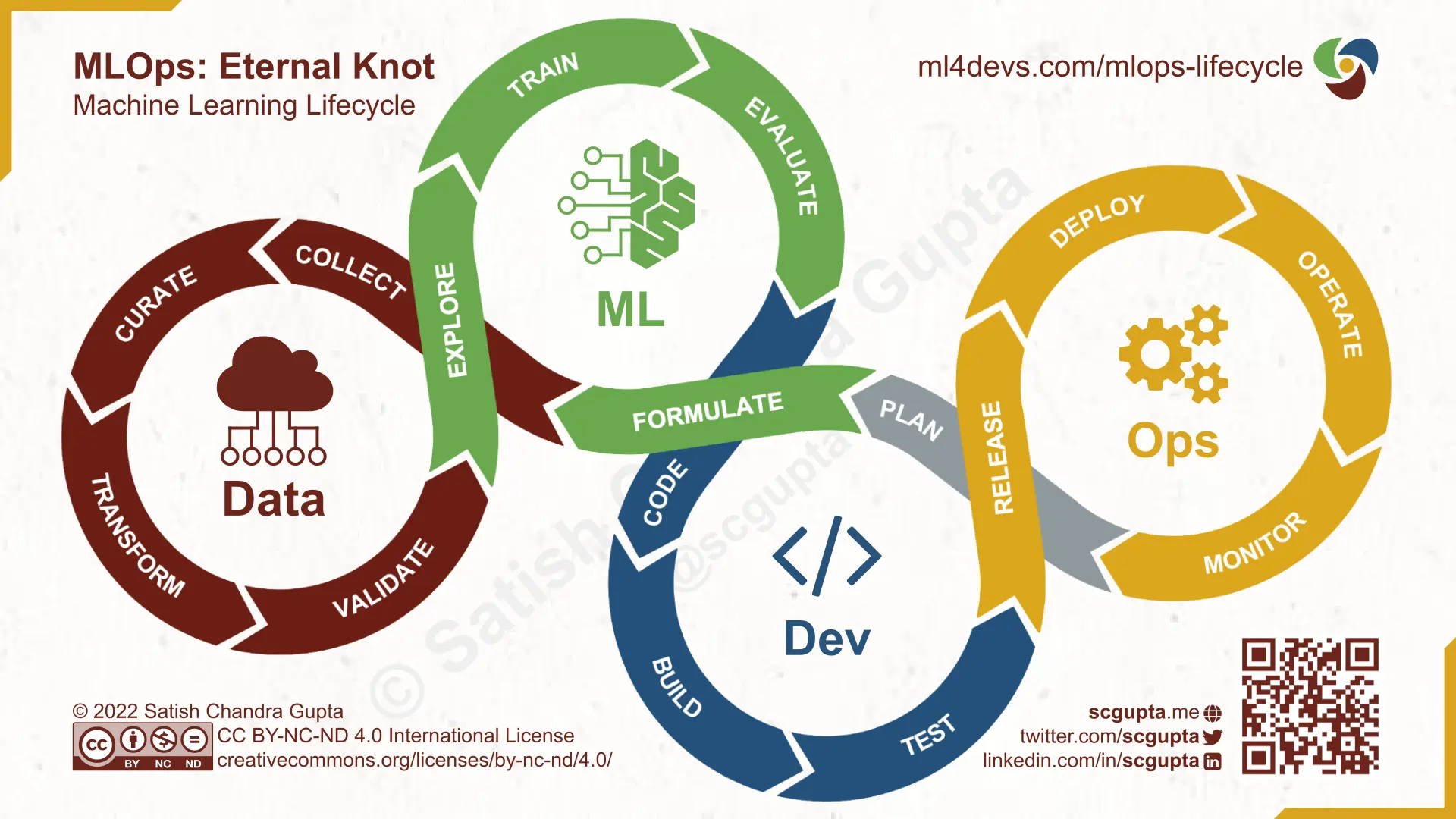
MLOps stands for Machine Learning Operations. It is a set of practices to continuously train, integrate, and deploy (CT/CI/CD) Machine Learning models in production. It is inspired by DevOps practices followed in software development.
MLOps is for managing the entire Machine Learning lifecycle — from formulating an ML problem from business objectives to operating and monitoring ML models in production.
Should You Care?
It depends on what stage your project is.
Despite all the hype around MLOps, a large number of data science teams still practice the waterfall lifecycle in ML projects. Data Scientists experiment and train a model and then “toss it over to the wall” for engineers to deploy it to production.
Presumably, many of these teams successfully deploy ML models in production. Maybe they fail often and the whole thing is chaotic and frustrating for everyone involved (myself included). But they succeed too, and that is remarkable.
We should make our process smoother and adopt best practices to increase the success rate, but we should not blindly follow FAANG. What is best at Google-scale is most likely wasteful and expensive for small and medium companies. Not everyone needs to train models every hour, day, or week.
Investment in advanced practices and tools should be made with clarity about the additional returns it will yield in the short, medium, and long term.
For that, one must know the value current practices — waterfall lifecycles — can deliver. Training and deploying models manually is good enough if you deploy a couple of models once in a few months. Focus on what will move the needle in your business.
Why Should You Care? How Much?
If you have half a dozen models or more and deploy monthly or more often, then you should consider adopting MLOps progressively taking one loop at a time. After mastering the current level, you move to the next level only if the resulting value justifies the efforts.
Level 0: Manual
Your data scientists manually gather data, clean and transform it, train models, pick and validate the best, and give it to your engineers to deploy.
Level 1: Continuous Data
The aim is to automate your data pipeline. You are most likely already doing parts of it for your data analytics. The data is automatically and continuously collected, stored, validated, transformed, and fed to live analytics dashboards.
You need to augment the pipeline to compute features needed for model training and store it in a feature store, add statistical checks to the data validation, and a dashboard for the statistical distribution of key features.
Level 2: Continuous Training
The aim is to automate the model training pipeline to train models on new data. You automate the data validation checks you added in the previous step. Now you trigger training either at a frequency or manually whenever is needed, and voila, your training pipeline trains a model on new data.
Data scientists manually validate the model, verify the output distributions, etc., and had it over to an engineer like they have been doing to deploy it in production.
Level 3: Continuous Integration
The aim is to automate the handoff of models from data scientists to engineers. You automate the pipeline for the model validation (what data scientists were doing manually), model [service] integration and testing with the rest of the application (what engineers were doing manually).
Your application may already be continuously deployed. But you still pay a bit extra attention whenever you roll out a new model, manually watch its predictions, application features it affects, latencies, system loads, etc.
Level 4: Continuous Deployment
The aim is to automate the pipeline for canary deployment, A/B testing, rollback, model monitoring, and triggering model training when necessary.
Now you have reached the pinnacle of automating CT/CI/CD of your model, but also CI/CD of the pipeline that does it. Welcome to the FAANG club! Just kidding 😃
What Do You Think?
I would love to hear from you about your experiences (DM me on Twitter or Linkedin):
- How does your org/team/project function? What process do you follow?
- What is working out well for you, and what gives you nightmares?
- Do you care about all the buzz in MLOps? Why or why not?