“Pipeline” is an overloaded term in data science and machine learning. People mean different things when they talk about data pipelines or ML pipelines. This issue covers the 3 most common kinds of pipelines: data pipelines, machine learning pipelines, and MLOps pipelines.
Data Pipelines
Data pipelines are the most ancient among the 3. These have been around for over 25 years. It has two variants: Extract-Transform-Load (ETL) and Extract-Load-Transform (ELT).
ETL pipelines transform the data before storing it. ELT pipelines clean the data, store it as close to raw form as feasible, and then run transformations (and store their results too). As the transformation step evolves, ELT pipelines can simply rerun it on the raw data.
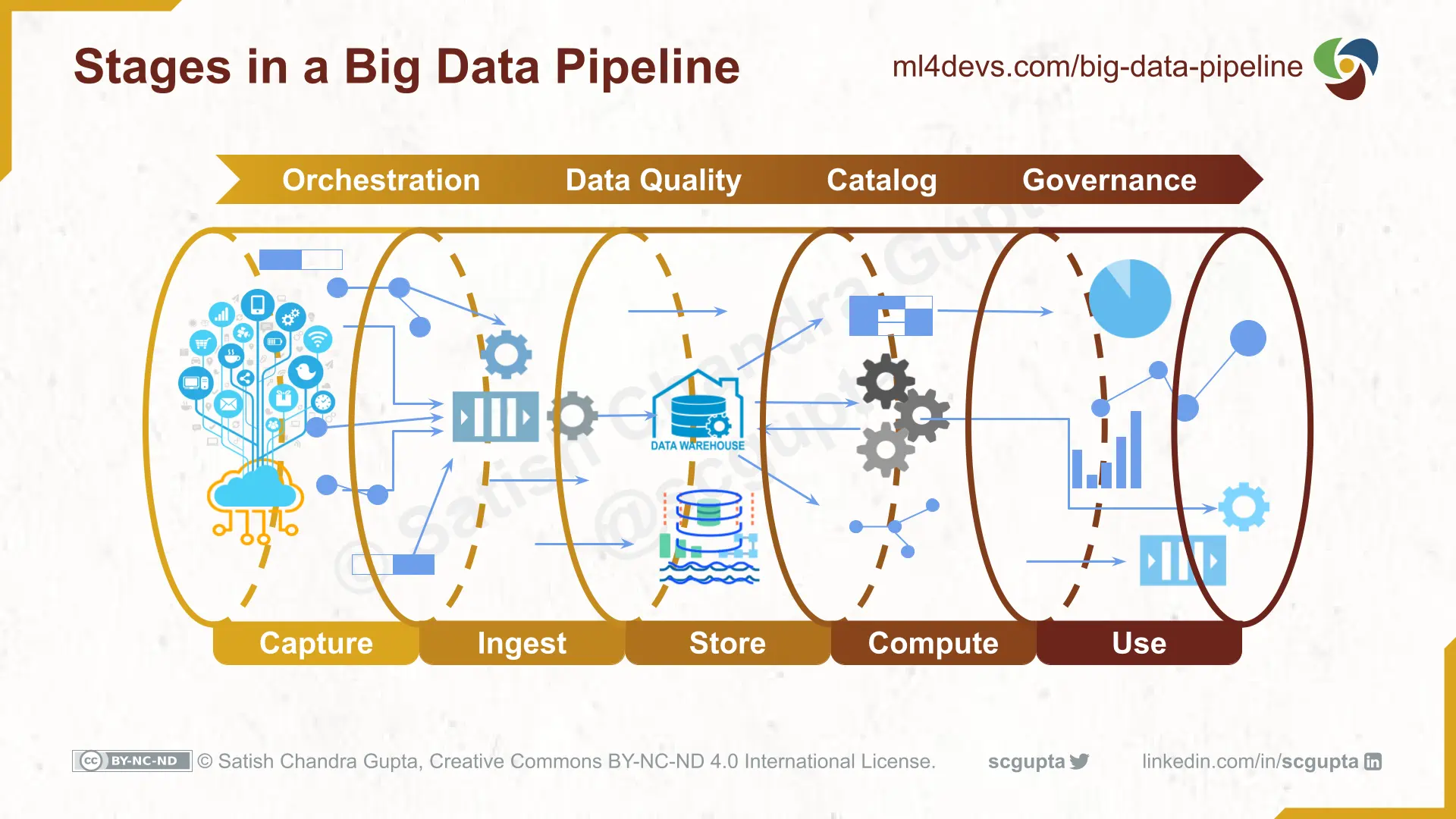
Data Pipelines automate the process of collecting, cleaning, and persisting data in a Data Warehouse or Data Lake. It has 5 stages:
- Capture data from internal and external sources
- Ingest data through batch jobs or streams
- Store data (after cleaning) in a data warehouse or data lake
- Compute analytics aggregations and ML features
- Use it in BI dashboards, data science, ML, etc.
Batch Data Pipelines process data in batch at a configured frequency. Streaming Data Pipelines process data events in real time as they arrive. You can build data pipelines on-premise or on the cloud.
Machine Learning Pipelines
Machine Learning has two phases:
- Training: Run experiments to train several machine learning models, tune hyper-parameters, and select the best model. It has load-transform-fit steps.
- Inference: Predict the outcome using the model on new input data. It has load-transform-predict steps.
Each of these steps can be coded separately. Data Scientists often do that, especially when using Jupyter Notebooks. It causes two problems:
- Code Comprehension: It is difficult to understand the code there transformation is scattered all over the place.
- Train-Infer Bugs: When the data transformations for training and inference are scattered and duplicated, it is quite possible that one is modified while the other is not. That can cause silent bugs.
Almost all major Machine Learning frameworks offer a way to define a chain of data transformations to perform feature extraction and selection, which is then fed to the fit or predict step:
These ML pipelines are sometimes called Data Input pipelines.
MLOps Pipelines
MLOps pipelines orchestrate machine learning workflows in MLOps Lifecycle for continuous integration, deployment, and training (CI/CD/CT) of ML models.
Here is the MLOps pipeline suggested by Google:
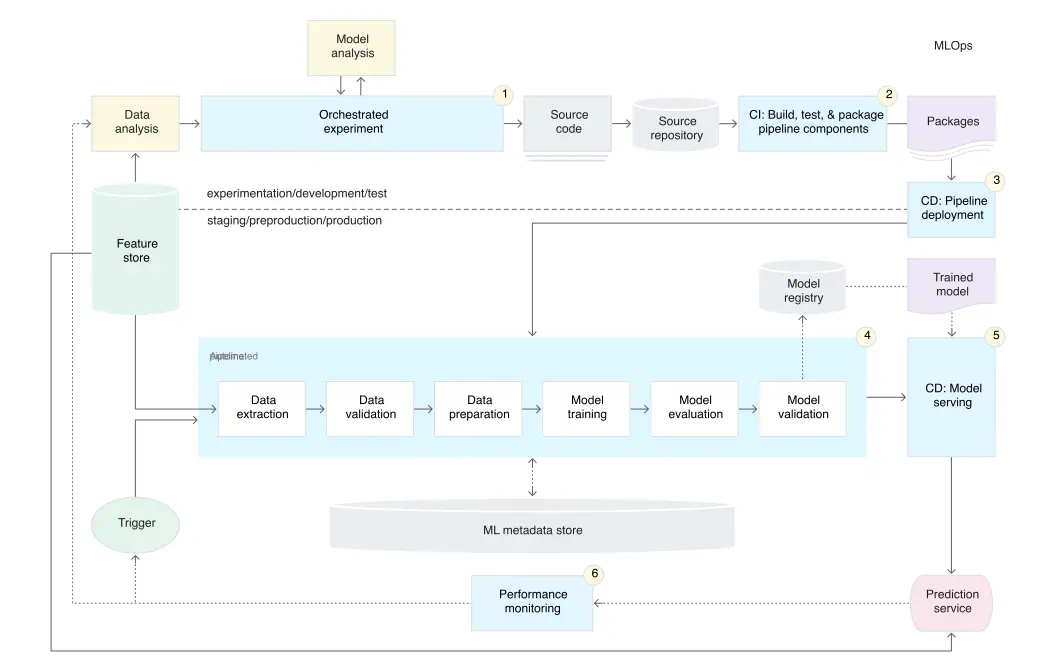
All major model deployment infrastructure/frameworks offer MLOps pipelines:
- TFX Pipelines
- KubeFlow Pipelines
- Google Vertex AI Pipelines
- AWS SageMaker Pipelines
- MLFlow Pipelines
Fuzzy Boundaries
The boundaries between the 3 aren’t cast in stone. Parts of the ML pipelines for feature extraction are often moved to the Data Pipeline. Data standardization, normalization, encoding, etc., are often done close to the model training, so remain in the ML pipeline. However, hyperparameter selection (e.g. Grid Search) is better suited to be in the MLOps pipeline.
The goal of this issue is to give an overview of the landscape and options. You choose what is most suitable for your use case.